A Practical Exploration of Mixed-Style Response LLMs via Few-Shot LoRA Fine-Tuning
1. Research Background and Motivation
With the increasingly widespread application of Large Language Models (LLMs) today, how to make model outputs more transparent, natural, and understandable has become an important research direction. Traditional LLMs typically output the final answer directly, making their internal reasoning process a "black box" to the user. To enhance the interpretability of interaction, we explored a mixed-style response mechanism.
The core idea of this mechanism is to have the model's response mimic the human "thinking out loud" pattern, consisting of alternating segments of "internal reasoning" and "external answer". Specifically:
- Internal Reasoning: This is the model's real-time reasoning process, including problem decomposition, logical deduction, and fact-checking.
- External Answer: This is the final conclusion or intermediate answers presented to the user, wrapped with specific tags <|answer_start|> and <|answer_end|>.
Our goal was not to train a new model with this capability from scratch, but rather to use efficient fine-tuning techniques to enable an existing general-purpose LLM to learn this complex response format.
2. Research Methods and Process
2.1 Model and Base Selection
We selected Qwen3-14B as our base model. This is a powerful, open-source 14-billion-parameter model with strong general knowledge and reasoning capabilities as a foundation.
2.2 Fine-Tuning Technique and Dataset
- Fine-Tuning Technique: We employed LoRA (Low-Rank Adaptation). The advantage of LoRA lies in its high parameter efficiency for fine-tuning large models. It only requires training a low-rank decomposition subset of the original parameters, significantly reducing computational costs and hardware requirements, making it highly suitable for rapid iteration and experimentation.
- Dataset: We meticulously constructed a dataset containing 1000 samples. Each sample strictly adheres to the mixed-style response rules, containing alternating internal reasoning and tagged external answers, designed to teach the model this specific output format.
2.3 Training and Challenges
The training process focused on teaching the model two things: first, how to conduct effective "internal reasoning" to progress towards a solution; and second, when and at what pace to insert the external answer tags. Given the small dataset size (only 1000 samples), our main challenge was ensuring the model could solidly grasp this complex rule and possess good generalization capabilities.
Dataset: dianzinao/deepseek-v3-distill-RWA-1000
3. Research Results and Observations
After LoRA fine-tuning, we observed the following results in testing:
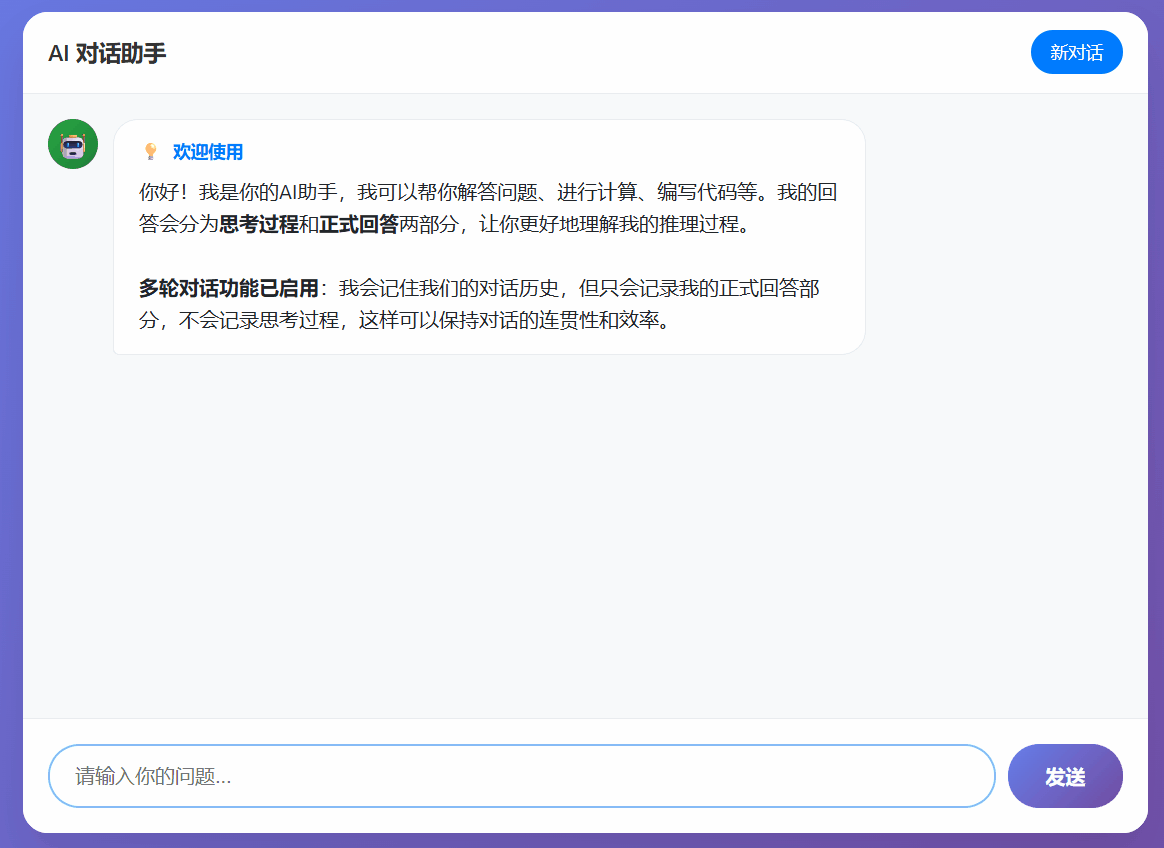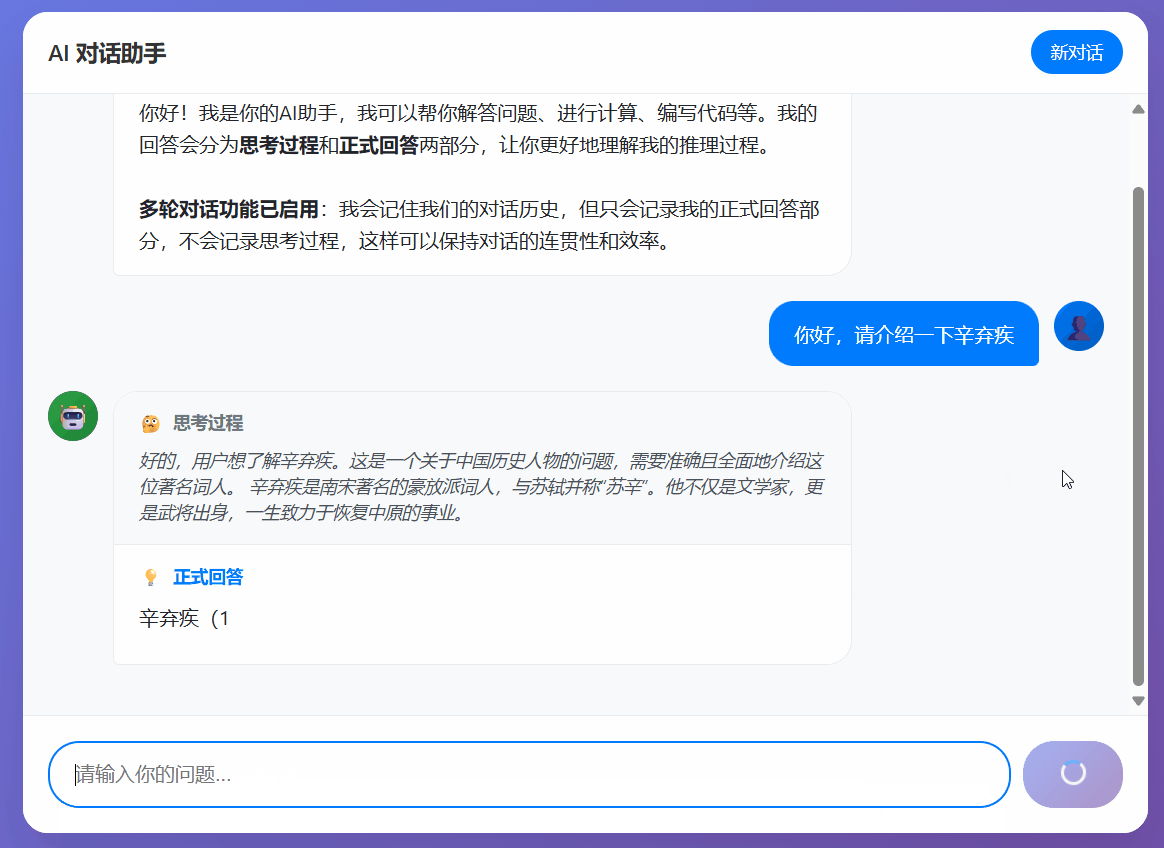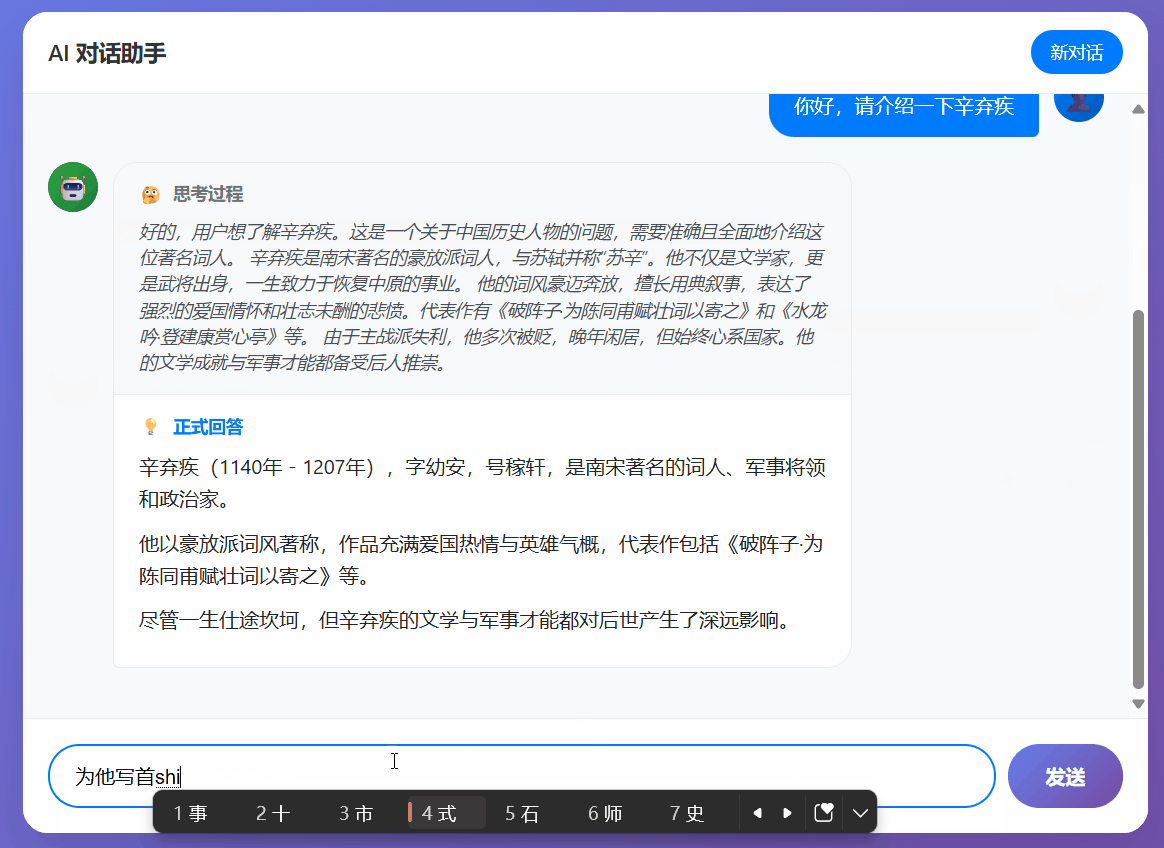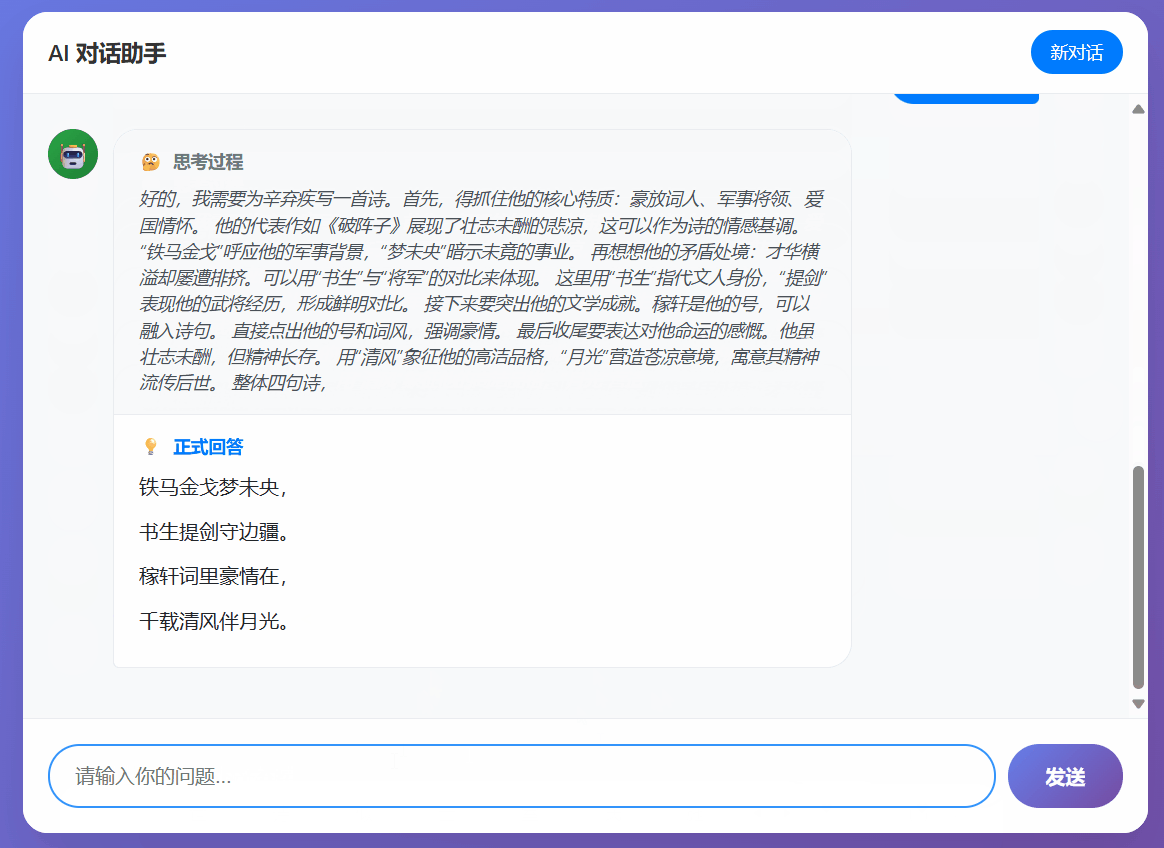
- Effective in Single-Turn Dialogue: In single Q&A scenarios, the fine-tuned model performed reasonably well. It successfully generated logically coherent internal reasoning processes according to the specified rules and accurately used the <|answer_start|> and <|answer_end|> tags to output answer segments at key points. This demonstrates that even with a few-shot dataset, LoRA fine-tuning can effectively teach a model a new, complex output style.
- Significant Limitations in Multi-Turn Dialogue: As anticipated, due to the limited dataset size and potential lack of optimization for multi-turn dialogues, the model performed poorly in consecutive conversations. A typical issue was that the model might forget to add answer tags, or its response pattern in subsequent turns would revert to a basic conversational style, failing to consistently maintain the mixed-style response rules. This indicates that the model's grasp of the rules is not yet deep enough to handle more complex dialogue states.
4. Online Demo and Summary
We have deployed this fine-tuned model on a website for experience and discussion:
🌐 Demo Address: https://chat.dianzinao.cn
Summary:
This practice successfully validated the feasibility of using a small-scale dataset (1000 samples) and LoRA fine-tuning to equip an existing large model (Qwen3-14B) with the specific interactive capability of mixed-style response. The model's performance in single-turn dialogues met the expected goal, proving the effectiveness of this technical approach.
Simultaneously, we clearly observed its limitations, particularly the insufficient ability to maintain rules in multi-turn dialogues. This points the way for future work: addressing this issue may require expanding and enriching the training dataset, especially by adding more multi-turn dialogue samples, or exploring other fine-tuning strategies to enhance the model's ability to follow long-term instructions.
This study provides a low-cost, reproducible practical case for exploring transparent and interpretable AI interaction methods.